Проект: RAG система для каталога ювелирных изделий
Система Retrieval-Augmented Generation с семантическим кэшированием и переиндексацией внутренней базы знаний
Задачи проекта:
- Разработка системы семантического поиска для ювелирных каталогов
- Реализация двухуровневого хранилища (основной индекс + кэш вопросов/ответов)
- Автоматическая индексация документов с обнаружением изменений
- Интеграция семантического кэширования для оптимизации запросов
- Возможность автоматической очистки семантического кэша по времени устаревания
- Возможность ручной очистки семантического кэша
Описание проекта:
RAG система для каталога ювелирных изделий — это профессиональное решение для работы с каталогами ювелирных изделий, использующее подход Retrieval-Augmented Generation с возможностями семантического кэширования. Система интегрирует ChromaDB для векторного поиска, HuggingFace для эмбеддингов и OpenAI GPT для генерации ответов.
Архитектура решения
Общая архитектура
Система состоит из следующих основных компонентов:
- Двухуровневое хранилище (ChromaDB для документов и отдельная коллекция для кэша)
- Автоматическая индексация с обнаружением изменений через хеши SHA-256
- Семантическое кэширование с TTL-истечением и инвалидацией по источнику
- Поддержка различных форматов документов (JSON, PDF, DOCX, TXT)
Ключевые компоненты
VectorDatabase (ChromaDB)
- Управление коллекциями ChromaDB для документов и кэша
- Методы для добавления/удаления документов
- Очистка устаревших записей кэша
RAG Рабочий процесс
- Проверка кэша перед обработкой запроса
- Поиск релевантных документов при отсутствии кэша
- Генерация ответа с LLM и сохранение в кэш
Обработка документов
- Поддержка JSON, PDF, DOCX, TXT форматов
- Использование библиотеки Unstructured для извлечения текста
- Разбиение на чанки с перекрытием
Конфигурация
- Настройка путей ChromaDB
- Параметры обработки документов
- Настройки моделей и кэширования
Технический стек
- Backend: Python 3.9+
- Векторная БД: ChromaDB
- Эмбеддинги: HuggingFace (all-MiniLM-L6-v2)
- Языковая модель: OpenAI GPT
- Обработка текста: Unstructured, LangChain
Ключевые особенности:
Семантический поиск
- Использование эмбеддингов HuggingFace
- Точное извлечение релевантной информации
Система кэширования
- Семантическое сопоставление с порогом расстояния L2
- TTL-истечение (настраивается)
- Инвалидация по источнику
Автоматическая индексация
- Обнаружение изменений через хеши SHA-256
- Инкрементальные обновления
- Очистка удаленных файлов
Поддерживаемые форматы
- JSON - прямой парсинг с проверкой хешей
- PDF/DOCX - извлечение через Unstructured
- TXT - прямая обработка текста
Режимы работы:
- Очистка данных: Удаление индексов ChromaDB
- Индексация документов: Обработка файлов в data/
- Интерактивный чат: Интерфейс вопросов и ответов
- Тестовые вопросы: Предопределенный набор вопросов
- Очистка кэша: Удаление семантического кэша
Схема обработки запроса

Скриншоты проекта
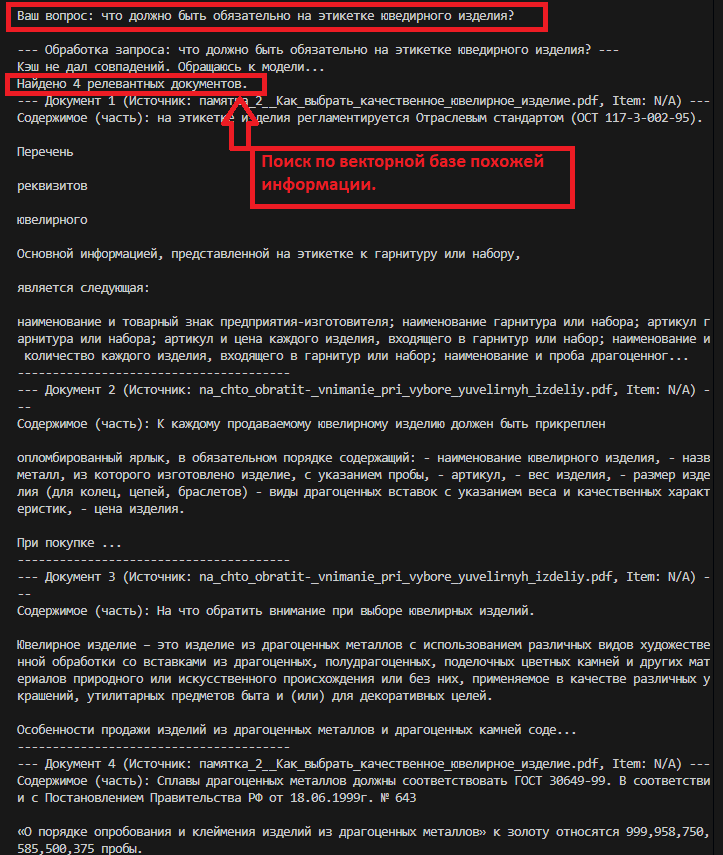
Пример запроса 1: анализ - RAG - документ из БЗ (PDF) - LLM - ответ.
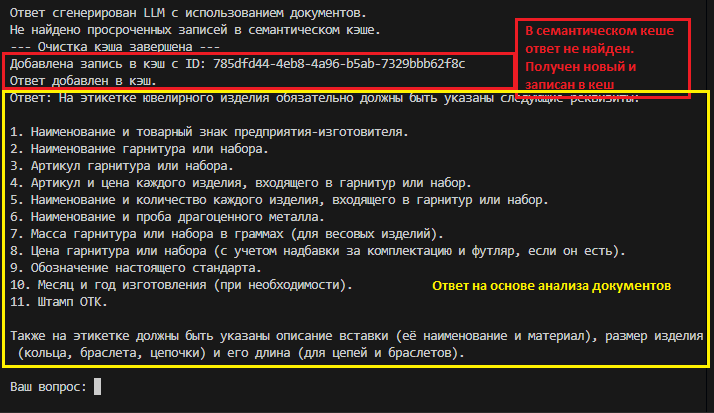

Пример запроса 2: анализ - RAG - документ из БЗ (TXT) - LLM - ответ - кеш.

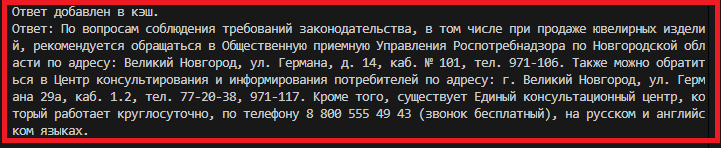
Пример запроса 3: анализ - найден подобный в кеше - ответ из кеша.

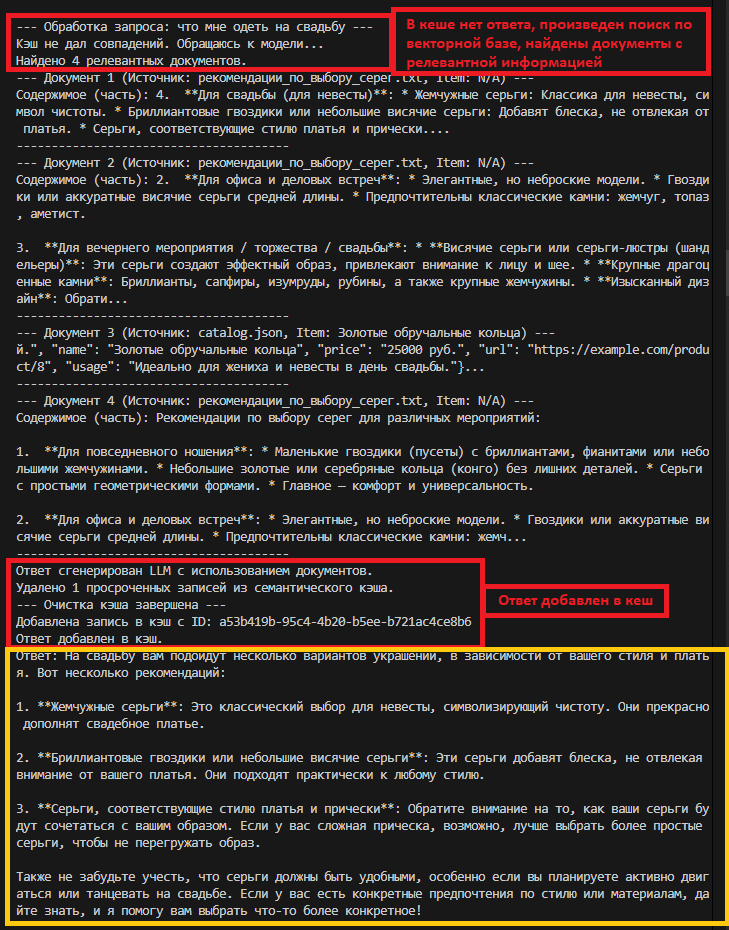
Пример запроса 4: анализ - RAG - документ из БЗ (JSON) - LLM - ответ - кеш.
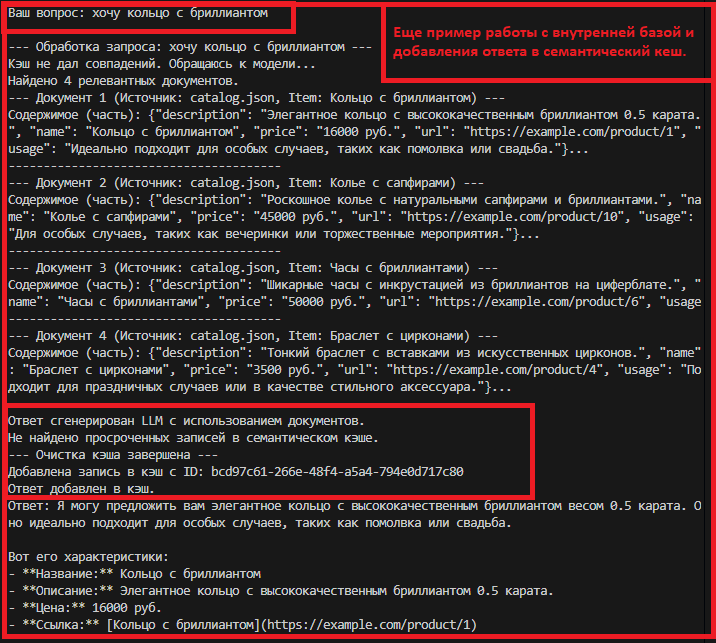
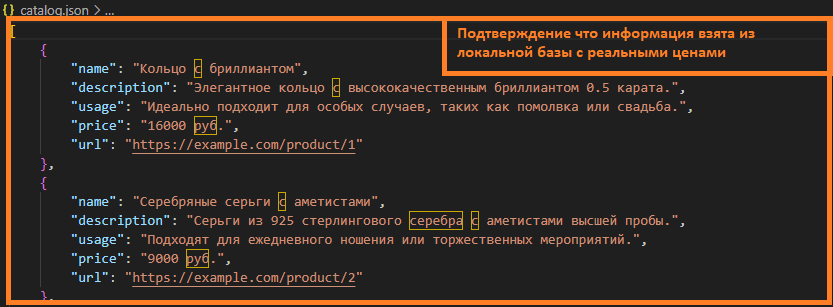
Пример запроса 5: анализ - RAG - документ из БЗ (DOC) - LLM - ответ.